I. Introduction
Qui nía jamais eu de problèmes pour
lire un document qui est fourni par un tiers même si ce document a été créé
avec une application identique à celle utilisée par le destinataire ?
Je
peux affirmer sans crainte : personne !
I.1 Petit état
des lieux
Prenons au hasard
l'exemple des documents réalisés avec le logiciel Word de Microsoft.
Edifiant ! Avec une même version de ce logiciel, sur
une plate-forme différente voir même sur une plate-forme identique, la lecture
d'un document peut s'avérer compliquée. Au mieux le contenu est lisible, mais
la forme n'est pas celle de l'original et au pire le document est illisible.
Ce problème est extrêmement pénalisant et gênant dans une
société comme la nôtre où les échanges de documents sont vitaux pour la bonne
marche des entreprises.
Il existe bien évidemment des formats compréhensibles et
lisibles par tous, les fichiers textes aussi appelés ASCII (American Standard
Code of Information Interchange) mais le formatage est inexistant. D'autres formats
comme RTF (Rich Text Format) apportent un plus, mais il reste toujours le
problème de la compatibilité et de la structuration des documents.
Les textes créés oublient souvent un ou plusieurs des
éléments qui constituent un document ou une série de documents. La plupart du
temps, les documents possèdent les deux premiers c'est à dire le contenu
et le format mais rares sont ceux qui sont en plus structurés.
Les premiers formats, toujours très utilisés comme TEX (1978 Initiales grecs de
technologie), proposent des contenus fortement formatés mais sans réelle
structure. Aucune règle n'indique comment structurer le contenu (où se situe le
titre, les formules ...) ce qui, par conséquent, ne permet pas de systématiser
ou d'automatiser des outils de traitement de ces documents, pour effectuer des
recherches par exemple ou des modifications, des ajouts, des référencements.
Difficile aussi de réutiliser le document avec d'autres applications même si il
existe des traducteurs (html, ps ...).
I.2 Historique
Dès 1960, un éditeur New Yorkais,
Stanley Rice, propose l'idée de créer une structure générale de publication
unique. Norman Scharpf, directeur de GCA (Graphic Communication Association),
estime l'idée pertinente et crée un groupe de travail qui va travailler sur le
codage générique GenCode.
|
De l'association GCA (Graphic Communication Association)
sera fondée l'organisation IDEAlliance (International Digital Entreprise
Alliance) regroupant des entreprises comme Hachette, IBM, AOL, Oracle ...
(http://www.idealliance.org) |
|
En septembre 1967, William Tunnicliffe (président du
"Composition Committee" de la Graphic Communication Association
(GCA)) crée un nouveau groupe de travail le "GCA GenCode Committee "
pour travailler sur la recherche d'un code générique permettant de dissocier le
contenu de la structure d'un document.
Cíest ensuite, quíIBM grand créateur de documentation,
développe l'idée et crée en 1969 le GML (Generalized Markup Language) grâce à
Charles Goldfarb, Edward Mosher et Raymond Lorie. Leurs initiales forment le
sigle ... GML.
Ce format a alors un grand succès, prouvant par la même
occasion que cette voie est une bonne voie. L'ANSI (American National Standards
Institute) à travers son groupe de travail CIP (Committee on Information
Processing) constitue alors une équipe en y associant le GCA Gencode sous la
direction de Charles Goldfarb afin de développer un langage normalisé de
description de texte basé sur GML en 1970.
|
En 1983 une norme est proposée appelée SGML (Standard Generalized Markup Language). Elle est adoptée par le DoD (US Department of Defense)
ainsi que par les services fiscaux de ce même pays. |
|

De nombreuses applications sont alors créées élargissant
ainsi l'application de SGML à d'autres pays. En 1986, l'ISO (International
Organization for Standardization) reconnaît le SGML comme norme sous
l'appellation ISO8879:1986.
Mais que permet de faire le SGML ?
Le SGML est un méta-langage qui permet de créer des
sous-langages de balisage adaptés aux contenus de documents et qui propose à la
fois un formatage et une structuration forte de ce document. Il
peut donc s'adapter à n'importe quels contenus, des documents techniques,
médicaux, informatiques, juridiques ...
Le revers de cette ´ universalité ª est que SGML
est un monstre très complexe qui propose de très nombreux codes et syntaxes
pour s'adapter à tous les cas possibles de documents. Son utilisation est alors
réservée à de grosses structures (tel IBM) pouvant se permettre d'investir dans
de lourds développements.
Pour ces raisons ont émergé des types de documents
découlants de SGML mais simplifiés comme XML (eXtensible Markup Language) et en
1990 le plus connus HTML (HyperText Markup Language).
Ce dernier crée par deux chercheurs du CERN est très
largement répandu mais sa force : sa simplicité en fait aussi sa faiblesse. En
effet, la forme du contenu a largement pris le dessus sur la structuration du
document d'où actuellement un revirement qui tend a redonner une plus grande
structuration aux documents tout en essayant de conserver une certaine
simplicité. On voit arriver un compromis entre le XML et le HTML : le XHTML
(eXtensible HyperText Markup Language). Le XHTML est une restructuration de
HTML 4 en XML 1.0. La recommandation du W3c date du 26 Janvier 2000 voir
l'adresse internet http://www.w3.org/TR/xhtml1/.
XML ne remplace pas HTML mais tente de lui redonner une
vision plus générale de son code, permettant ainsi son utilisation dans
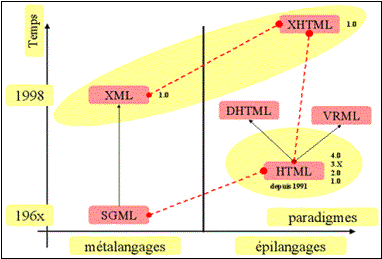
d'autres domaines que le simple affichage de contenus sur l'internet. XML est
un méta-langage tandis que HTML est un langage. A partir d'XML on peut créer
d'autres langages ; Par contre, HTML est lui un langage que líon peut
appeler terminal ou comme líindique le schéma suivant : un épilangage.
La figure suivante provient du site internet de xmlfr http://xmlfr.org/documentations/articles/000321-0001
I.3 XML aujourdíhui
XML est donc un méta-langage, un
ensemble de règles qui permettent de créer d'autres langages qui ont pour but
de créer des documents ´ universels ª respectant la même structure,
pouvant ainsi être plus facilement échangeables, pouvant être traduit dans
plusieurs formats (ps, pdf, text , xhtml, voix, ...), permettant d'en
extraire le contenu sans problème. XML peut donc être utilisé pour créer des
applications et des types de documents de tous ordres.
|
Voir le site internet http://www.W3.org/XML |
|
Il faut malgré tout dire que le XML est un produit jeune
même si ses parents sont assez âgés eux. XML est un méta langage mais, seul il
ne sert à rien. Gravite autour de lui une multitude díautres éléments quíil est
aussi nécessaire de connaître XSLT, DTD, schema, XLINK Ö
Cíest pourquoi il est encore assez difficile de trouver des
outils pour le traiter, des applications qui utilisent toute sa puissance.
Mais en informatique tout va très vite et sa réelle percée
peut être rapide comme díailleurs son extinction Ö
I.4 Pourquoi XML ?
Alors pour quelles raisons
utiliser XML plutôt que díautres formats plus courant et simple
díutilisation ?
Le site du w3c propose une réponse en 10 points contenue
dans le document suivant : http://www.w3.org/XML/1999/XML-in-10-points.fr.html
1. XML est
une méthode pour structurer des données
On entend par " données structurées " des
éléments tels que des feuilles de calcul, des carnets d'adresses, des
paramètres de configuration, des transactions financières, des dessins
techniques, etc. XML est un ensemble de règles, de lignes directrices, de
conventions (quel que soit le nom que vous voulez leur donner) pour la
conception de formats texte permettant de structurer des données. XML facilite
la réalisation de fichiers qui ne soient pas ambigus, et qui évitent les pièges
courants, tels que la non-extensibilité, l'absence de prise en charge de
l'internationalisation/localisation et la dépendance par rapport à certaines
plates-formes. XML est conforme à Unicode.
|
|
http://www.unicode.org |
2. XML ressemble un peu à HTML
Comme HTML, XML utilise des balises (des mots encadrés
par '<' et '>') et des attributs (de la forme nom="valeur"). Mais
alors que HTML
définit la signification de chaque balise et de chaque
attribut (et
souvent la manière dont le texte qu'ils encadrent
apparaîtra dans un
navigateur), XML utilise les balises seulement pour
délimiter les
éléments de données et laisse l'entière interprétation
des données à
l'application qui les lit. En d'autres termes, si vous
voyez "<p>" dans
un fichier XML, ne supposez pas qu'il s'agit d'un
paragraphe. Selon le contexte, cela peut être un prix, un paramètre, une
personne, un p...
(d'ailleurs, qui a dit qu'il devait s'agir d'un mot
commençant par "p" ?).
3. XML est du texte, mais il n'est pas destiné à être lu
Les programmes qui produisent de telles données les
stockent souvent sur disque, dans un format binaire ou un format texte. Ce
dernier format vous permet, si nécessaire, de consulter les données sans le
programme qui les a produites. Les fichiers XML sont des fichiers texte, mais
ils sont encore moins destinés à être lus par des individus que les fichiers
HTML. Ce sont des fichiers texte, car ils permettent à des experts (tels que
les programmeurs) de déboguer plus facilement des applications, et en cas
d'urgence, d'utiliser un simple éditeur de texte pour corriger un fichier XML
endommagé. Mais les règles des fichiers XML sont beaucoup plus strictes que
celles des fichiers HTML. Une balise oubliée ou un attribut sans guillemets
rendent le fichier inutilisable, alors qu'avec HTML, de telles pratiques sont
souvent explicitement permises, ou au moins tolérées. Les spécifications officielles
de XML indiquent que les applications ne sont pas autorisées à essayer de
deviner ce qu'a voulu faire le créateur d'un fichier XML endommagé ; si le
fichier est endommagé, une application doit s'arrêter immédiatement et émettre
une erreur.
4. XML est bavard, mais ce n'est pas un problème
Comme XML est un format texte et qu'il utilise des
balises pour
délimiter les données, les fichiers XML sont presque
toujours d'une
taille plus importante que les formats binaires
équivalents. Il s'agit
là d'une décision prise en toute conscience par les
développeurs de XML. Les avantages d'un format texte sont évidents (voir le
point 3
ci-dessus), et ses inconvénients peuvent être
généralement compensés à un autre niveau. L'espace disque n'est plus aussi coûteux
qu'auparavant, et les programmes tels que zip et gzip
(http://www.gnu.org/software/gzip/gzip.html) compressent
très bien et
très rapidement les fichiers. De plus, les protocoles de
communication
tels que les protocoles de modem et HTTP/1.1 ftp://ftp.nordu.net/rfc/rfc2616.txt (le protocole de base du Web) peuvent compresser des données
à la volée, ce qui économise de la bande passante aussi efficacement qu'un
format binaire.
5. XML est une famille de technologies
Il existe XML 1.0 http://www.w3.org/TR/REC-xml, la spécification qui
définit ce que sont les "balises" et les
"attributs", mais autour de
cette spécification, un nombre de plus en plus important
de modules
facultatifs fournissant des ensembles de balises et
d'attributs ou des
lignes directrices pour des tâches particulières ont été
définis. C'est,
par exemple, le cas de Xlink, qui décrit une méthode
standard pour ajouter des liens hypertextes à un fichier XML. Xpointer et
XFragments sont des syntaxes pour pointer sur des parties d'un document XML. Un
XPointer ressemble à un URL, mais au lieu de pointer sur des documents du Web,
il pointe sur des éléments de données au sein d'un fichier XML. CSS le langage
des feuilles de style, s'applique à XML de la même façon qu'à HTML. XSL est le
langage évolué pour la définition de feuilles de style. Il est basé sur XSLT ,
un langage de transformation utilisé pour réorganiser, ajouter ou supprimer des
balises et des attributs. Le DOM est un ensemble
d'appels de fonctions standard pour manipuler des
fichiers XML (et HTML) à partir d'un langage de programmation. Les Schémas XML
1
et 2 aident
les développeurs à définir précisément leurs propres formats basés sur XML.
Plusieurs autres modules et outils sont disponibles ou en cours de
développement.
Consultez régulièrement la page des rapports techniques
du W3C.
6. XML est nouveau, mais pas si nouveau que ça
Le développement de XML a commencé en 1996, et XML est
une norme du W3C depuis février 1998, ce qui peut laisser supposer qu'il s'agit
d'une technologie plutôt immature. En fait, il ne s'agit pas d'une technologie
très nouvelle. Avant XML, il existait SGML, développé au début des années 80,
devenu norme ISO depuis 1986 et largement utilisé dans des projets de
documentation de taille importante. Et il existait bien sûr HTML, dont le
développement a commencé en 1990. Les concepteurs de XML ont simplement pris
les meilleures parties de SGML, profité de l'expérience de HTML, et produit une
technologie qui n'est pas moins puissante que SGML, mais infiniment plus
régulière et plus simple à utiliser. Certaines évolutions, cependant, peuvent
être assimilées à des révolutions... Il faut également savoir que SGML est
principalement utilisé pour des documentations techniques et beaucoup moins
pour d'autres types de données, alors que c'est exactement l'inverse avec XML.
7. XML conduit HTML à XHTML
Une application importante d'XML est le langage XHTML
comme successeur de HTML. On retrouve dans XHTML beaucoup d'éléments du langage
HTML. La syntaxe a été légèrement modifiée afin de se conformer aux règles
d'XML.
Plus généralement, un document fondé sur XML hérite sa
syntaxe d'XML modulo quelques exceptions : par exemple, XHTML autorise la
balise "<p>" mais pas "<r>". XML ajoute aussi
un sens à cette syntaxe : par exemple, XHTML dit que "<p>"
signifie "paragraphe" et non "prix" ou "personne"
ou etc.
8. XML est modulaire
XML permet de définir un nouveau format de document en
associant et en réutilisant d'autres formats. Cependant, deux formats
développés indépendamment peuvent avoir des éléments ou attributs de même nom.
Il faut alors être très attentif à ne pas confondre les noms :
"<p>" signifie-t-il "paragraphe" ou
"personne" ? Pour éviter toute confusion lors de l'association de
noms identiques, XML fournit un mécanisme d'espaces de nom . XSL et RDF sont de bons exemples de technologies
fondées sur XML qui utilisent les espaces de nom. XML Schema http://www.w3.org/XML/Schema a été conçu pour répercuter
cette fonctionnalité modulaire pour la définition des
structures XML, puisqu'il est facile de combiner deux
schémas pour en produire un troisième qui sera associé au document fusionné.
9. XML est le fondement de RDF et du Web Sémantique
RDF, la norme du W3C pour les métadonnées, est un texte
au format XML qui autorise la description de ressources et les applications
métadonnées, tels que recueils de musiques, albums photos, et bibliographies.
Par exemple, RDF pourrait vous laisser identifier des
personnes dans un album photo sur le Web en utilisant des
informations puisées dans une liste de contacts ; puis, votre messagerie
pourrait automatiquement envoyer un message prévenant les personnes que leurs
photos sont sur le Web. Tout comme les éléments HTML intégrés, comme les menus
et formulaires, RDF intègre les applications et les agents en un Web
Sémantique. De la même manière que les humains ont besoin de se mettre d'accord
sur les mots qu'ils utilisent en communicant entre eux, les machines ont aussi
besoin de mécanismes pour communiquer efficacement. Les descriptions formelles
de terminologies dans un domaine particulier (la grande distribution ou
l'industrie, par exemple) sont appelées ontologies, et sont une partie
nécessaire du Web Sémantique. RDF, ontologies, et la représentation des
connaissances sont tous des sujets décrits dans l'activité Web Sémantique .
10. XML est libre de droits, indépendant des plates-formes et correctement pris en charge
En
choisissant XML pour un projet, vous bénéficiez d'un ensemble
important
et sans cesse croissant d'outils (et il est possible que l'un
d'eux
remplisse déjà la fonction dont vous avez besoin !) et d'ingénieurs
expérimentés dans cette technologie. Opter pour XML, c'est un peu comme choisir
SQL pour des bases de données : vous devez encore construire votre propre base
de données et vos propres programmes ou procédures qui la manipulent, mais un
grand nombre d'outils et d'individus peuvent vous y aider. Et comme XML est
libre de droits, vous pouvez vous en servir pour construire votre propre
logiciel sans avoir à payer quoi que ce soit à qui que ce soit. Sa prise en
charge est importante, et ne cesse de croître, ce qui signifie également que
vous n'êtes pas lié à un seul fournisseur. XML n'est pas toujours lameilleure
solution, mais il vaut toujours la peine d'être pris en considération.
I.5 Les sites de référence et la
bibliographie
ÿ
Les
sites de référence
|
Vous trouverez une liste de site sur celui du ministère
de l'éducation nationale |
|
Sinon voici certains sites incontournables :
|
Logo du site
et/ou intitulé |
Adresse
internet |
|
|
http://www.w3.org/xml |
|
|
http://xml.apache.org |
|
|
http://www.atica.gouv.fr |
|
|
http://www.xmltechno.com |
|
|
http://www.xmlfr.org |
|
|
http://www.mutu-xml.org |
|
|
http://www.xmlsoftware.com/ |


ÿ
Les
livres
Couverture
|
Titre du livre |
Edition |
|
|
Introduction
à XML |
Oíreilly |
|
|
XML web tr@ining |
OEM |
|
|
XML pour
le world wide web |
Peachpit |


